karpenter spot fallback
개요
컴퓨팅 비용 절감의 가장 확실한 방법은 적절한 리소스 최적화(right-sizing)와 스팟 인스턴스 활용입니다.
Karpenter와 Karpenter의 Fallback 기능을 사용하면 스팟 인스턴스를 중단 없이 사용할 수 있습니다.
환경
- EKS 1.32
- Karpenter 1.8.1 (official helm chart)
- Node Termination Handler 1.25.2 (official helm chart)
- NTH 동작 모드는 IMDS(Instance Metadata Service) 모드로 설정했으며, 데몬셋으로 배포됨
설정 가이드
Spot Service-Linked Role 생성
Spot 인스턴스를 사용하려면 AWS 계정에 EC2 Spot용 Service-Linked Role(AWSServiceRoleForEC2Spot)이 존재해야 합니다. 이 역할이 없으면 Karpenter가 Spot 인스턴스를 생성할 수 없고 Fallback(On-demand)으로만 노드가 생성됩니다.
Service-Linked Role은 AWS 서비스가 사용자를 대신하여 다른 AWS 리소스를 관리할 때 필요한 특수한 IAM 역할입니다. Spot 인스턴스의 경우 가격 모니터링, 용량 관리, 인스턴스 중단 처리 등의 작업을 수행하기 위해 이 역할이 필요합니다.
Service-Linked Role이 없는 경우 Karpenter 로그에서 다음과 같은 에러가 발생합니다.
{
"level": "ERROR",
"message": "failed launching nodeclaim",
"error": "creating instance, insufficient capacity, with fleet error(s), AuthFailure.ServiceLinkedRoleCreationNotPermitted: The provided credentials do not have permission to create the service-linked role for EC2 Spot Instances."
}AWS CLI로 Service-Linked Role을 생성합니다. 계정당 한 번만 생성하면 됩니다.
aws iam create-service-linked-role --aws-service-name spot.amazonaws.comAWS 콘솔에서 Spot 인스턴스를 처음 요청하면 자동 생성되지만, Karpenter처럼 API로 직접 요청할 때는 자동 생성되지 않아서 수동으로 생성해야 합니다.
노드 프로비저닝
Karpenter가 노드 프로비저닝하는 과정의 트리거는 Pending 상태의 파드가 있는 시점
---
title: Karpenter node provisioning
---
flowchart LR
p["`Pods
Pending`"]
subgraph k8s[Kubernetes Cluster]
direction LR
subgraph cp["Control Plane"]
kas["kube-apiserver"]
end
subgraph kube-system
k["`**Pod**
karpenter`"]
end
k --> np
k -- Watch --> p
k e1@--Create nodeclaim--> nodeclaim
np[nodepool] --> ec2nc[ec2nodeclass]
end
subgraph wn["Wokrer Node (EC2)"]
kubelet["`**kubelet**
controlled by systemd`"]
end
nodeclaim e2@--Create EC2 via IAM Role--> wn
kubelet --Join cluster--> kas
style np fill:darkorange,color:#fff,stroke:#333
style ec2nc fill:darkorange,color:#fff,stroke:#333
e1@{ animate: true }
e2@{ animate: true }
linkStyle 2 stroke:darkorange,stroke-width:2px
linkStyle 4 stroke:darkorange,stroke-width:2pxKarpenter 헬름차트 구조
Karpenter 설치는 공식 헬름 차트로 쉽게 진행할 수 있습니다. Karpenter v0.32.0부터 OCI registry로 마이그레이션되었습니다.
karpenter 차트 다운로드:
# 버전 검색
crane ls public.ecr.aws/karpenter/karpenter
# OCI 차트 저장소에서 karpenter 차트 다운로드
helm pull oci://public.ecr.aws/karpenter/karpenter --version 1.8.1 --untar---
title: Karpenter helm chart
---
flowchart LR
admin["👨🏻💼 Cluster Admin"]
admin --helm install--> Main["`**Chart**
karpenter`"]
admin --helm install--> Sub["`**Sub Chart**
karpenter-nodepool`"]
subgraph k8s[Kubernetes Cluster]
direction LR
subgraph kube-system
Main --> Controller["`**Pod**
karpenter`"]
end
Sub --> NodePool["`CR
nodepool`"]
Sub --> EC2NC["`CR
ec2nodeclass`"]
Controller -.-> NodePool
Controller -.-> EC2NC
end
style Main fill:#6c5ce7,color:#fff,stroke:#333
style Sub fill:#6c5ce7,color:#fff,stroke:#333Karpenter의 커스텀 리소스를 담고있는 karpenter-nodepool 차트는 공식 제공되는 차트가 아니라 직접 개발해서 운영중입니다.
헬름차트로 Karpenter를 관리하는 이유는 복잡한 Kubernetes 리소스들을 템플릿화하여 환경별 설정값(dev/stage/prod)을 values.yaml 파일로 분리 관리할 수 있고, 차트 버전 기반의 원자적 배포와 즉시 롤백이 가능하기 때문입니다. 특히 Karpenter는 NodePool, EC2NodeClass 등 여러 CRD와 RBAC 설정이 복합적으로 연결되어 있어 헬름의 의존성 관리와 훅(hook) 기능을 활용하면 배포 순서 제어와 설정 일관성을 보장할 수 있으며, GitOps 워크플로우와 결합하여 인프라 변경사항을 코드로 추적하고 검토할 수 있어 운영 안정성이 크게 향상됩니다.
스팟 중단 핸들링 방법
Karpenter가 스팟 중단신호(Spot Interruption Notice)를 안전하게 처리하는 핸들링 방식은 크게 2가지입니다.
- Karpenter + Node Termination Handler
- EventBridge Rules + SQS + Karpenter
Karpenter 공식문서의 FAQ 페이지에서는 SQS를 사용하는 방식을 권장하고 있지만, NTH를 사용하는 방식이 운영 편의성이 더 좋습니다.
Karpenter가 노드 프로비저닝하며 NTH(Node Termination Handler)가 Spot 중단신호 감지 및 파드 Eviction 담당
flowchart LR
subgraph k8s[Kubernetes Cluster]
direction LR
k["`**Pod**
karpenter`"]
note1["Node Termination Handler is running on IMDS mode"]
note2["`⚠️ Karpenter 공식문서 페이지[1]에서는 Node Termination Handler를 같이 사용하지 않는 것을 권장하고 있음`"]
subgraph node1["Karpenter Node (Spot)"]
direction LR
nth1["`**DaemonSet Pod**
node-termination-handler`"]
imds1["`**IMDS**
169.254.169.254`"]
end
subgraph node2["Karpenter Node (Spot)"]
direction LR
nth2["`**DaemonSet Pod**
node-termination-handler`"]
imds2["`**IMDS**
169.254.169.254`"]
end
end
spotitn["Spot Interruption Notice"]
k --Node provisioning--> node1
k --Node provisioning--> node2
nth1 e1@--Handling Spot ITN--> imds1
nth2 e2@--Handling Spot ITN--> imds2
spotitn -.->|Send Spot ITN| imds1
spotitn -.->|Send Spot ITN| imds2
note1 ~~~ note2
style k fill:darkorange,color:#fff,stroke:#333
style note1 fill:transparent,color:#fff,stroke:#333
style note2 fill:transparent,color:#fff,stroke:#333
e1@{ animate: true }
e2@{ animate: true }1: https://karpenter.sh/docs/faq/#interruption-handling
Spot Nodepool Fallback
Fallback 기능을 사용하여 가중치(Weight) 기반 spot, on-demand 노드풀 선정
노드풀의 가중치(Weight) 설정
nodepool 리소스에 spec.weight 필드를 사용하여 가중치(Weight)를 설정하면 됩니다.
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: batch
spec:
template:
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
weight: 100 # Set 10 for fallback on-demand nodepoolKarpenter는 같은 할당 조건을 가진 노드풀 중에서 가중치가 높은 노드풀을 우선 선택합니다. 높은 가중치의 노드에 할당이 실패하면 가중치가 낮은 노드에 할당을 시도합니다.
파드 설정에서도 기본(스팟) 노드풀과 Fallback 노드풀에 대한 nodeAffinity를 모두 지정해야 합니다.
apiVersion: v1
kind: Pod
metadata:
name: my-pod
namespace: default
labels:
app: my-app
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: karpenter.sh/nodepool
operator: In
values:
- batch # Set primary(spot) nodepool
- batch-fallback # Set fallback(on-demand) nodepoolKarpenter 노드는 생성될 떄 자동으로 자신의 노드풀 이름이 담긴 karpenter.sh/nodepool 라벨이 붙습니다. 이 라벨을 사용해서 파드를 특정 노드풀과 폴백 노드풀에 할당할 수 있습니다.
시스템 아키텍처:
flowchart LR
subgraph k8s[Kubernetes Cluster]
direction LR
pod["`**Pod**
(Pending)`"]
subgraph kube-system
karpenter["`**Pod**
karpenter`"]
end
np-batch["`**nodepool**
batch
Weight: 100`"]
np-batch-fallback["`**nodepool**
batch-fallback
Weight: 10`"]
nc["nodeclaim"]
end
node["`EC2
Worker Node`"]
karpenter --Watch--> pod
karpenter --> np-batch
np-batch -->|"❌ 리소스 부족"| np-batch-fallback
np-batch -->|"✅ 리소스 충분"| node
np-batch-fallback --> nc --Create EC2--> node
style np-batch fill:darkorange,color:#fff,stroke:#333
style np-batch-fallback fill:darkorange,color:#fff,stroke:#333노드 프로비저닝 과정이 시작되면 Karpenter Controller는 노드풀의 가중치(Weight)를 참고하여 가중치가 높은 스팟 노드풀을 우선 선택합니다. 만약 스팟 노드풀의 리소스가 부족하면 Fallback 노드풀이 선택됩니다.
AWS Summit Seoul 2025에서 샌드버드가 발표한 'Amazon EKS 기반 클라우드 최적화와 생성형 AI 혁신 전략' 세션에서 많은 부분을 참고했습니다.
메트릭 수집 설정
Karpenter는 노드풀 및 클러스터 수준의 거시적인 메트릭을 제공합니다.
prometheus-operator를 사용하는 경우, 서비스 모니터링을 위해 노드풀 레벨의 메트릭을 수집하기 위해 servicemontior 리소스 생성합니다.
아래는 Karpenter 헬름 차트의 설정 예시입니다.
# charts/karpenter/values_your.yaml
serviceMonitor:
# -- Specifies whether a ServiceMonitor should be created.
enabled: true메트릭 수집 과정
flowchart LR
subgraph k8s[Kubernetes Cluster]
direction LR
subgraph kube-system
k["`**Pod**
karpenter`"]
svc["`**Service**
ClusterIP`"]
smon["servicemonitor"]
end
prom["`**Pod**
prometheus-server`"]
promop["`**Pod**
prometheus-operator`"]
promcfg["`**Secret**
Scrape Config`"]
promop --Watch--> smon --> svc --> k
promop --Update--> promcfg
promcfg --Mount--> prom e1@--Scrape /metrics--> svc e2@--> k
end
e1@{ animate: true }
e2@{ animate: true }Prometheus Server가 Karpenter 서비스의 /metrics 엔드포인트에 접근하여 메트릭을 수집합니다.
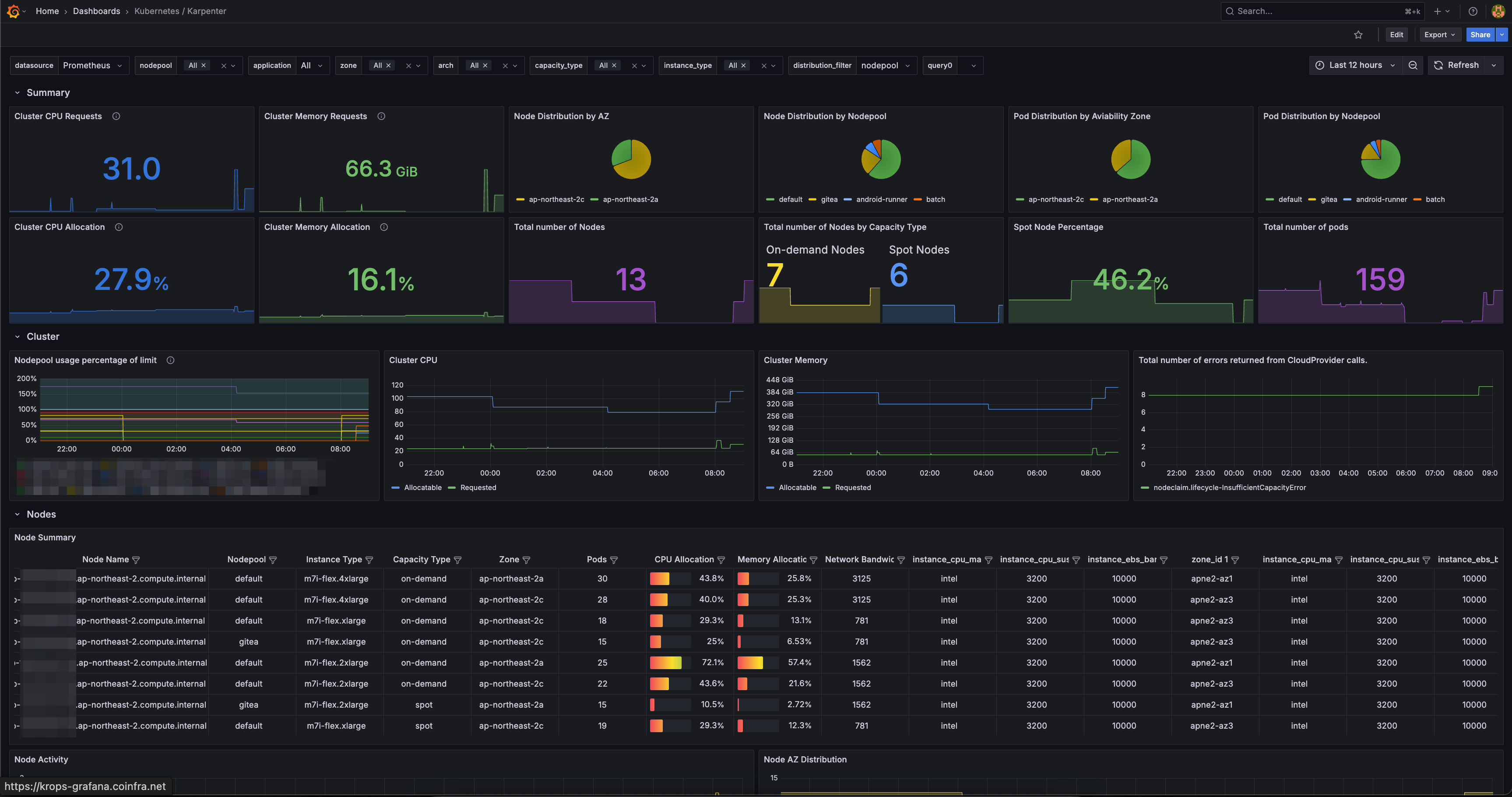
Grafana 대시보드
가시성(Observability)을 높이기 위해 Grafana 대시보드와 Prometheus 메트릭을 연동하여 Karpenter의 성능과 상태를 실시간으로 모니터링할 수 있습니다.
flowchart LR
user["Users"]
subgraph k8s[Kubernetes Cluster]
direction LR
kp["`**Pod**
karpenter`"]
ks["`**Service**
ClusterIP`"]
dash["`**Grafana**
Dashboard`"]
prom["`**Pod**
prometheus-server`"]
end
user --View--> dash
prom --Scrape /metrics--> ks --> kp
dash --Query--> prom
style kp fill:darkorange,color:#fff,stroke:#333Grafana 대시보드 ID 20398를 통해 노드풀, 스팟 현황 및 비중, 노드 레벨의 리소스 사용률을 확인할 수 있습니다.
TLDR
Karpenter 1.8.1 + NTH 조합에 Spot fallback을 사용해본 결과 5개월 동안 스팟 중단으로 인한 영향도는 없었습니다. 결과적으로 클러스터의 80~85% 스팟 노드를 안정적으로 운영했습니다.
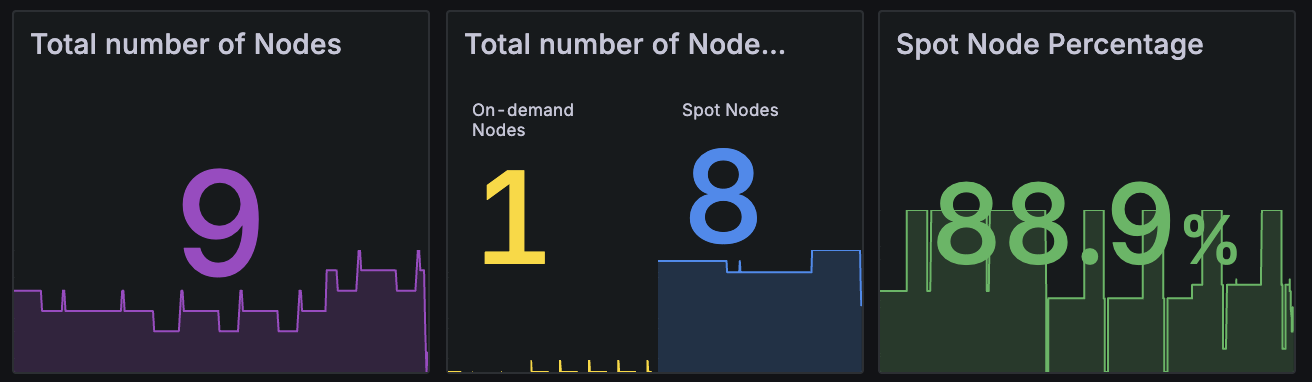
위 그래프는 Grafana 대시보드에서 확인한 Karpenter의 Capacity Type별 노드 비율입니다. Spot 인스턴스 비율이 전체의 80~85% 수준으로 안정적으로 유지되고 있으며, 나머지 15~20%는 Fallback용 On-Demand 인스턴스로 구성되어 있습니다.
아래는 kubectl 명령어로 스팟 노드 목록을 조회한 예시입니다.
kubectl get node -l karpenter.sh/capacity-type=spotNAME STATUS ROLES AGE VERSION
ip-xx-xxx-xx-xxx.ap-northeast-2.compute.internal Ready <none> 8d v1.32.9-eks-113cf36
ip-xx-xxx-xx-xx.ap-northeast-2.compute.internal Ready <none> 23h v1.32.9-eks-113cf36
ip-xx-xxx-xx-xx.ap-northeast-2.compute.internal Ready <none> 13h v1.32.9-eks-113cf36
ip-xx-xxx-xx-xxx.ap-northeast-2.compute.internal Ready <none> 10d v1.32.9-eks-113cf36
ip-xx-xxx-xx-xxx.ap-northeast-2.compute.internal Ready <none> 65m v1.32.9-eks-113cf36
ip-xx-xxx-xx-xx.ap-northeast-2.compute.internal Ready <none> 29m v1.32.9-eks-113cf36
ip-xx-xxx-xx-xxx.ap-northeast-2.compute.internal Ready <none> 13d v1.32.9-eks-113cf36Spot과 Fallback 노드풀 활용을 통해 EC2 비용 120 USD / 1mo 절감, 월비용으로는 3600 USD 절감되었습니다.