reconcile

Photo by Pawel Czerwinski on Unsplash
Best practices for keeping Kubernetes alive.
One card. One principle.
Define your resources
No requests? The scheduler guesses where to put you. No limits? One pod eats the whole node.
CPU limits — handle with care. Throttling kills latency.
Separate your probes
Readiness blocks traffic. Liveness kills the container.
If your app boots slow and only liveness fires, you'll loop forever. Use a startupProbe.
:latest is a trap
Moving tags break rollback. Same manifest, different image. Not reproducible.
Pin to SHA digest when you can — it catches supply-chain tampering too.
PDB is your insurance
Node drains happen every week. No PodDisruptionBudget means cluster upgrades become outages.
At minimum: minAvailable: 1.
RBAC: least privilege
cluster-admin on the default ServiceAccount is suicide.
One SA per workload. Only the verbs you need. Wildcards get revoked the moment debugging ends.
Spread your pods
Three replicas on one node? Availability is fiction.
Use topologySpreadConstraints to scatter across nodes and zones.
Run as non-root
runAsNonRoot: truereadOnlyRootFilesystem: truecapabilities.drop: [ALL]
Half of container-escape incidents close with these three lines.
Default deny
Without NetworkPolicy, every pod can reach every pod. A highway for lateral movement.
Default deny per namespace. Open by allow-list.
Native admission policy first
ValidatingAdmissionPolicy and MutatingAdmissionPolicy ship with the API server. CEL expressions evaluated in-tree — no controller pod, no admission webhook to keep healthy.
Reach for Kyverno only when you need cross-resource mutation, image verification, or report generation the natives don't cover.
Don't store secrets in plaintext
A secret committed to Git is a secret leaked forever. Plain Kubernetes Secrets in etcd aren't much better — base64 isn't encryption.
Keep the source of truth in HashiCorp Vault (or your cloud secrets manager) and sync into the cluster with External Secrets Operator.
Then turn on etcd encryption at rest for what's already inside.
Log to stdout
Write to a file → sidecars, rotation, full disks.
12-factor: write to stdout. Collection is infrastructure's job.
One stack, not five charts
Prometheus, Alertmanager, Grafana, kube-state-metrics, node-exporter — wiring them as five separate Helm releases means version drift and broken ServiceMonitor references.
kube-prometheus-stack ships them as one tested bundle, glued together by the Prometheus Operator.
Override what you need. Let the rest stay in sync.
Lower your ndots
The default ndots: 5 tries five search domains before resolving an external name. DNS traffic balloons. So does latency.
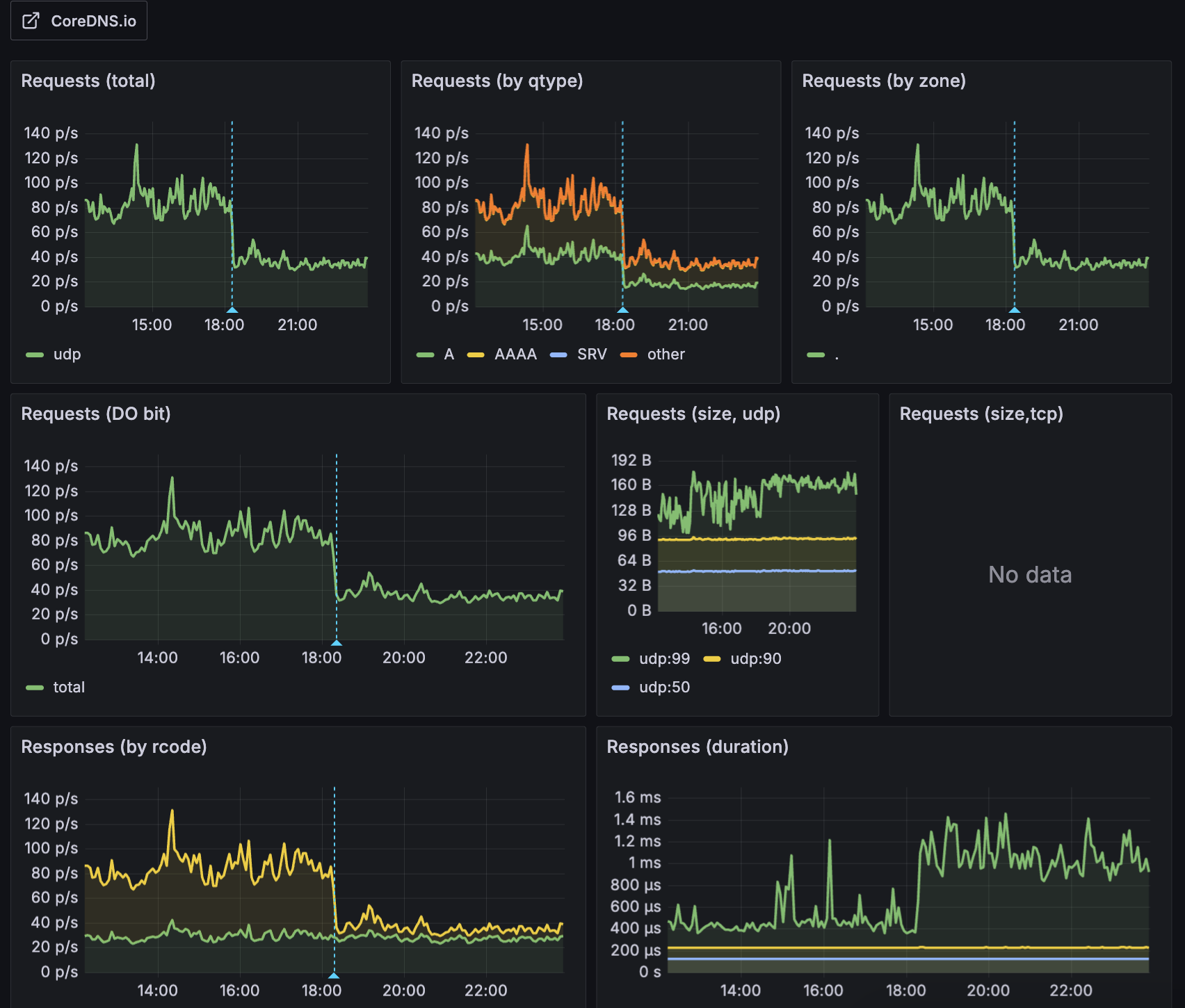
On a cluster with 7 nodes and ~130 pods, switching ArgoCD from ndots: 5 to ndots: 2 cut total DNS query volume by 56%.
For most workloads, dnsConfig.options.ndots: 2 is enough. Pair it with NodeLocal DNSCache to keep lookups on the node and shave off the round-trip to CoreDNS.
Deploy with GitOps
kubectl apply trusts human hands.
Put desired state in Git, let ArgoCD or Flux reconcile. The cluster converges, no questions asked.
That's it.
The principles are simple. Living by them isn't.